Gradient Descent
จากบทความ Machine Learning ตอนที่2 ที่เราได้รู้จักสมการ Cost function และเป้าหมายของเราที่จะ Minimize Cost function  ของเราแต่คำถามคือแล้วเราจะเริ่มต้นได้อย่างไร
ของเราแต่คำถามคือแล้วเราจะเริ่มต้นได้อย่างไร
ลองนึกภาพการลงจากเขาเมื่อคุณอยู่ที่ตำแหน่งหนึ่งบนยอดเขา และเป้าหมายของเราคือมองไปรอบๆเพื่อหาทางที่สั้นที่สุดที่จะลงไปถึงหุบเขา เมื่อได้ทิศทางที่เห็นว่าสั้นที่สุดก็จะก้าวไปหนึ่งก้าว และหลังจากนั้นก็จะมองไปรอบๆอีกครั้งเพื่อหาทางที่จะก้าวต่อไปจนลงไปถึงบริเวณที่ต่ำที่สุด วิธีนี้เรียกว่า “Gradient Descent” ซึ่ง Gradient Descent ไม่ได้เพียงใช้หาค่า Minimize ใน Linear Regression และยังสามารถใช้ในอัลกอริทึมอื่นๆที่จะกล่าวในบทความถัดไป
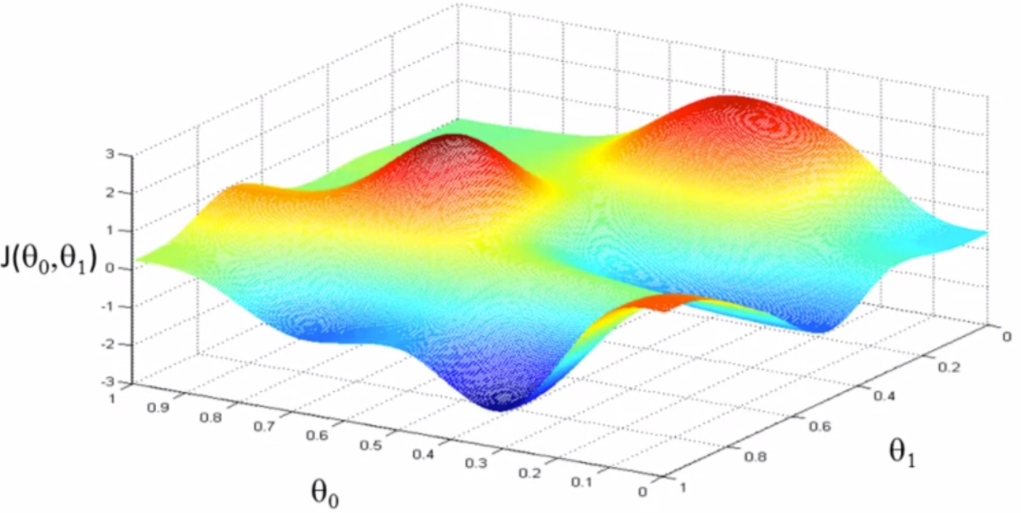
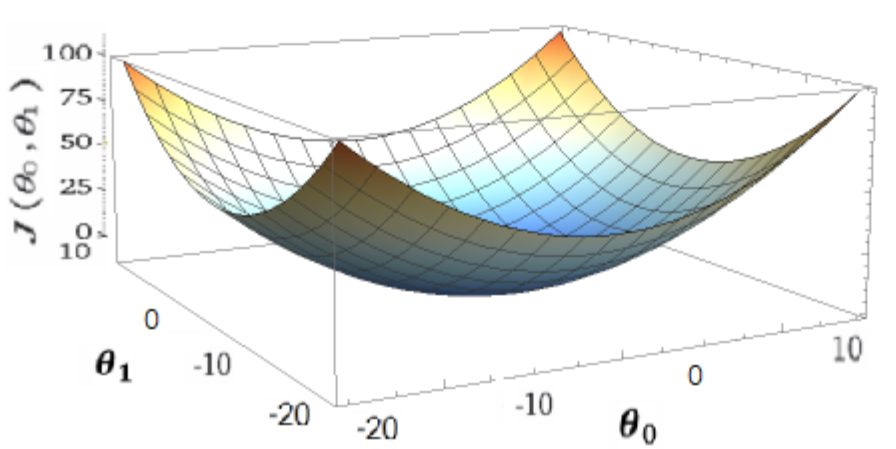
กลับมาที่เรื่อง training set ที่เรามี ก็เปรียบเสมือนกับภูเขาที่อาจจะมีเนินชันหรือไม่ชัน เส้นทางอาจจะซับซ้อนหรือไม่ซับซ้อน อาจจะมียอดเขาและหุบเขามากกว่าหนึ่งตำแหน่งและมีจุดที่ต่ำที่สุดเราจะเรียกว่า “Global Optimum” ส่วนหุบเขาในแต่ละตำแหน่งเราจะเรียกว่า “Local Optimum” ดังที่ได้แสดงในรูป 3.1 แต่ในกรณีที่ training set ของเราสามารถใช้อัลกอริทึม Linear Regression ได้แสดงว่า ข้อมูลของเรา เหมือนรูป 3.2 ซึ่งจะไม่มี local optimum มีเพียง global optimum เพียงตำแหน่งเดียว และยังแสดงว่าจุด Optimum ของ มีเพียงจุดเดียว
เกริ่นกันมาพอสมควร ต่อไปเรามาดูสมาการและวิธีการหา Minimize โดย Gradient Descent ว่าจะเริ่มต้นอย่างไร
- กำหนดค่าเริ่มต้นของ0และ1 เช่น
 และ
และ - เปลี่ยนค่า
 และ
และ  เพื่อ ทำให้
เพื่อ ทำให้  มีค่าลดลงไปเรื่อยๆจนถึงค่าลู่เข้า (Repeate until convergence) โดยการแทนค่าใหม่ของ และ ลงใน สมการ 3.1 ที่เป็นการนำเอาวิธี Gradient Descent ไปใช้หา Minimum ของ Cost funtion
มีค่าลดลงไปเรื่อยๆจนถึงค่าลู่เข้า (Repeate until convergence) โดยการแทนค่าใหม่ของ และ ลงใน สมการ 3.1 ที่เป็นการนำเอาวิธี Gradient Descent ไปใช้หา Minimum ของ Cost funtion
 และ
และ 
![\[\theta_{่j} := \theta_{่j} - \alpha\frac{\partial}{\partial\theta_{j}}j(\theta_{0},\theta_{1}) ..........where....(j = 0 and j = 1 )............(3.1) \]](https://www.blogmun.com/wp-content/ql-cache/quicklatex.com-f71e9a72d40c03b463be16777cb7429b_l3.png "Rendered by QuickLaTeX.com")
![\[\theta_{่0} := \theta_{่0} - \alpha\frac{\partial}{\partial\theta_{0}}j(\theta_{0}) ....................................(3.2)\]](https://www.blogmun.com/wp-content/ql-cache/quicklatex.com-b593cb1929e1d6ad4ea5bd5b3907c095_l3.png "Rendered by QuickLaTeX.com")
![\[\theta_{่1} := \theta_{่1} - \alpha\frac{\partial}{\partial\theta_{1}}j(\theta_{1}) ....................................(3.3)\]](https://www.blogmun.com/wp-content/ql-cache/quicklatex.com-abcc7dbfe5384c19d2f3cdbf005a3715_l3.png "Rendered by QuickLaTeX.com")
จากสมการ3.1 เรามาทำความเข้าใจหลักการทำงานของสมการ Gradient Descentกัน เริ่มต้นจากทางซ้ายตัว  ในกรณีของเราคือ
ในกรณีของเราคือ  และ
และ  ซึ่งเราต้องอัพเดทค่า ทางซ้ายไปพร้อมๆกับทางขวาของเครื่องหมาย
ซึ่งเราต้องอัพเดทค่า ทางซ้ายไปพร้อมๆกับทางขวาของเครื่องหมาย  เราเรียกว่า “Simultaneous update” โดยเราต้องคิด และ ที่ละตัวดังสมการ(3.2 และ 3.3) แต่อัพเดทค่าทั้งสองหลังจากที่คำนวณครบทั้งสองค่าแล้ว ถัดมาสัญลักษณ์
เราเรียกว่า “Simultaneous update” โดยเราต้องคิด และ ที่ละตัวดังสมการ(3.2 และ 3.3) แต่อัพเดทค่าทั้งสองหลังจากที่คำนวณครบทั้งสองค่าแล้ว ถัดมาสัญลักษณ์  เรียกว่า “Learning rate” ซึ่งเป็นตัวที่กำหนดความเร็วในการ Train หรือ ถ้านึกถึงตัวอย่างข้างต้นเรื่องการเดินลงจากยอดเขา ก็ระยะห่างของก้าวแต่ละก้าว ถ้าค่า มาก ก้าวที่ก้าวก็จะใหญ่ที่จะเดินลงจากยอดเขา แต่ก็ไม่ใช่ว่ายิ่งเราใช้ค่า มากระบบของเราจะหาจุด Opimum ได้เร็วเพราะถ้าค่า มากเกินไปก็จะทำให้ระบบข้ามจุดที่ต่ำที่สุดไปได้นึกถึงการกระโดดไปมาบนปากหลุมแต่ลงไปไม่ได้เพราะก้าวใหญ่เกิน มากระบบของเราจะหาจุด Opimum ได้เร็วเพราะถ้าค่า มากเกินไปก็จะทำให้ระบบข้ามจุดที่ต่ำที่สุดไปได้นึกถึงการกระโดดไปมาบนปากหลุมแต่ลงไปไม่ได้เพราะก้าวใหญ่เกิน และก็ไม่ควรจะให้ค่าน้อยเกินไปเพราะจะทำให้ระบบของเราใช้เวลาการ Train ช้ามาก ซึ่งแม้ จะเป็นค่าคงที่แต่ก้าวแต่ละก้าวจะมีความห่างที่ไม่เท่ากัน จากรูปที่ 3.3A และ 3.3B ซึ่งก้าวที่เข้าใกล้จุด Optimum จะค่อยๆเล็กลงเรื่อยๆ จนถึงจุด convergence ก็จะได้จุด minimize ของ Squared error Cost function
เรียกว่า “Learning rate” ซึ่งเป็นตัวที่กำหนดความเร็วในการ Train หรือ ถ้านึกถึงตัวอย่างข้างต้นเรื่องการเดินลงจากยอดเขา ก็ระยะห่างของก้าวแต่ละก้าว ถ้าค่า มาก ก้าวที่ก้าวก็จะใหญ่ที่จะเดินลงจากยอดเขา แต่ก็ไม่ใช่ว่ายิ่งเราใช้ค่า มากระบบของเราจะหาจุด Opimum ได้เร็วเพราะถ้าค่า มากเกินไปก็จะทำให้ระบบข้ามจุดที่ต่ำที่สุดไปได้นึกถึงการกระโดดไปมาบนปากหลุมแต่ลงไปไม่ได้เพราะก้าวใหญ่เกิน มากระบบของเราจะหาจุด Opimum ได้เร็วเพราะถ้าค่า มากเกินไปก็จะทำให้ระบบข้ามจุดที่ต่ำที่สุดไปได้นึกถึงการกระโดดไปมาบนปากหลุมแต่ลงไปไม่ได้เพราะก้าวใหญ่เกิน และก็ไม่ควรจะให้ค่าน้อยเกินไปเพราะจะทำให้ระบบของเราใช้เวลาการ Train ช้ามาก ซึ่งแม้ จะเป็นค่าคงที่แต่ก้าวแต่ละก้าวจะมีความห่างที่ไม่เท่ากัน จากรูปที่ 3.3A และ 3.3B ซึ่งก้าวที่เข้าใกล้จุด Optimum จะค่อยๆเล็กลงเรื่อยๆ จนถึงจุด convergence ก็จะได้จุด minimize ของ Squared error Cost function
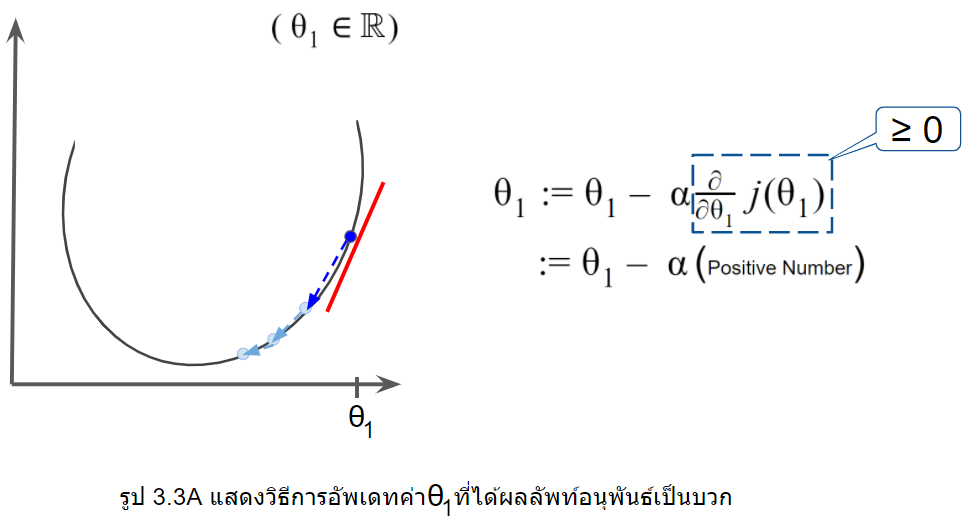
ถัดจาก คือส่วนของการอนุพันธ์ซึ่งจะเป็นส่วนสำคัญที่ทำให้ระบบรู้ว่าค่า ควรจะไปในทิศทางไหน จากรูป3.3A ให้ เป็นสมาชิกของเลขจำนวนจริง  ในขณะที่ slope เส้นสีแดงของเราเป็นค่าบวก(positive number) ดังนั้นค่า ก็จะลดลงเพราะค่า ลบกับค่าบวกนั่นเอง
ในขณะที่ slope เส้นสีแดงของเราเป็นค่าบวก(positive number) ดังนั้นค่า ก็จะลดลงเพราะค่า ลบกับค่าบวกนั่นเอง
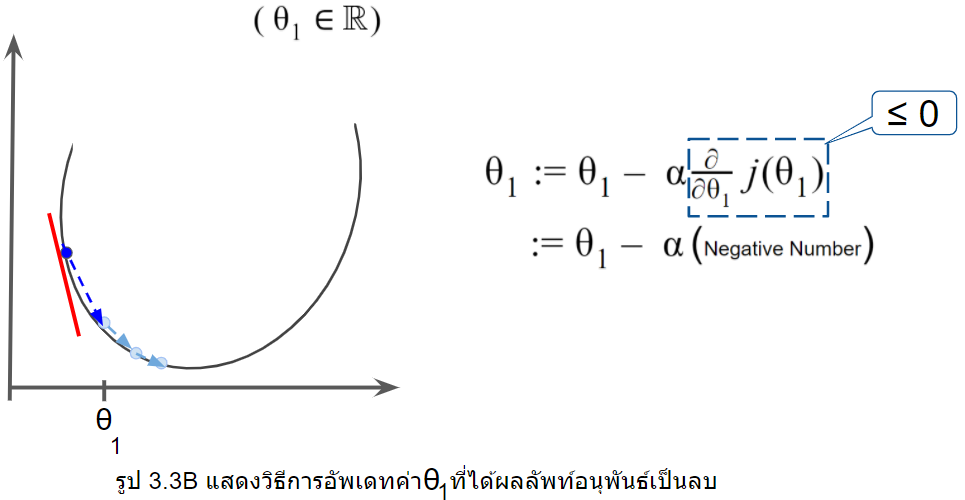
ในทางกลับกัน จากรูป3.3B ในขณะที่ slope เส้นสีแดงของเราเป็นค่าลบ(negative number) ดังนั้นค่า ก็จะเพิ่มขึ้นเพราะค่า ลบกับค่าลบ จึงกลายเป็นบวกกันนั่นเอง
![\[j(\theta_{0},\theta_{1}) = \frac{1}{2m}\sum_{i=1}^{m}(h_{\theta}(x^{(i)}-y^{(i)}))^{2}............................................(2.1)\]](https://www.blogmun.com/wp-content/ql-cache/quicklatex.com-1ef7e762ba4ca429fe86cacf4cd3ff9f_l3.png "Rendered by QuickLaTeX.com")
จากบทความในตอนที่ 2 สมการที่ 2.1 Squared error Cost function นำมาแทนใส่ในสมการ 3.1 เราจะได้ดังนี้
(1) 

ดังนั้นเมื่อ  และ
และ  ลงในสมการและหาอนุพันธ์จะได้ผลลัพท์ดังนี้
ลงในสมการและหาอนุพันธ์จะได้ผลลัพท์ดังนี้
(2) 
(3) 
และเมื่อนำกลับไปแทนในสมการ3.2 และ สมการ3.3 จะได้
Repeat Until Convergence {
(4) 
(5) 
}



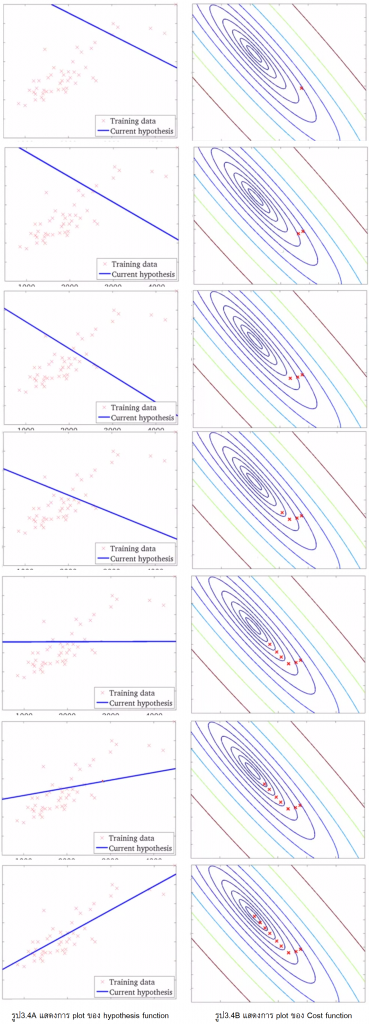
เมื่อทำการอัพเดทค่า และ ไปทีละstepเราก็จะเห็นได้ว่าระบบของเราพยายามจะหาค่าที่ Cost funtion น้อยลงไปเรื่อยจนเกิดการลู่เข้า Convergence จนทำให้ได้ค่า Minimize ของระบบนั้นๆดังที่แสดงให้เห็นในรูป 3.4
Multiple features (variables) with Gradient Descent
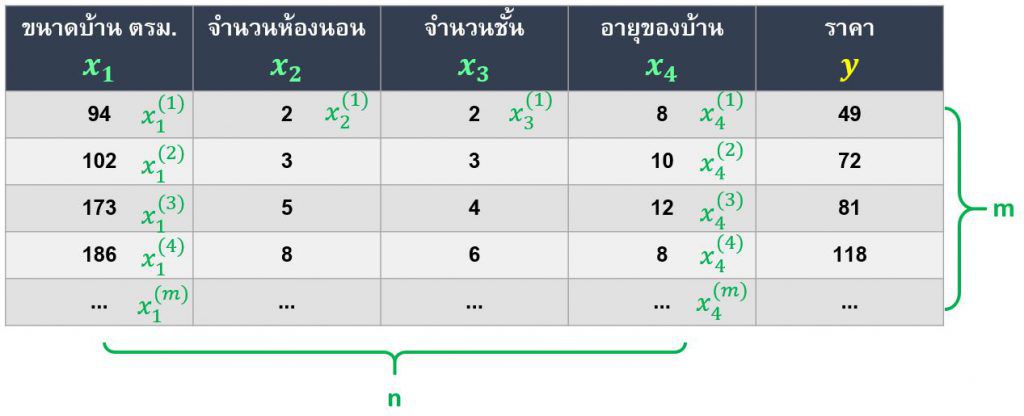
จากตัวอย่างข้างบนที่เรามีแค่ 1 ตัวแปรที่มีผลกับราคาบ้านก็คือขนาดพื้นที่ของบ้าน แล้วในกรณีที่เรามีตัวแปรมากกว่าหนึ่ง เช่น พื้นที่, จำนวนห้องนอน, จำนวนชั้น, อายุของบ้าน เป็นต้น (รูป 3.5) เราจะใช้อัลกอริทึม Gradient Descent ของเรากับข้อมูลของเราได้อย่างไร
จากสมการ Hypothesis ที่ใช้กับข้อมูล 1 ตัวแปร คือ
(6) 
และเมื่อเรามีตัวแปรที่เพิ่มขึ้น indexค่า ก็จะเพิ่มขึ้นตามจำนวนตัวแปรหรือตามจำนวน n ในตารางรูป 3.5
เราสามารถเรียกสมการนี้ว่า "Multivariate Linear Regression"
ดังนั้น
ก็จะเพิ่มขึ้นตามจำนวนตัวแปรหรือตามจำนวน n ในตารางรูป 3.5
เราสามารถเรียกสมการนี้ว่า "Multivariate Linear Regression"
ดังนั้น
(7) 
เราก็จะได้สมการ  ใหม่เพื่อเอาไปแทนในสมการ3.2 และ สมการ3.3 จะได้
Repeat Until Convergence {
ใหม่เพื่อเอาไปแทนในสมการ3.2 และ สมการ3.3 จะได้
Repeat Until Convergence {
(8)
(9)
(10)
(11) 
}

 ก็จะเพิ่มขึ้นตามจำนวนตัวแปรหรือตามจำนวน n ในตารางรูป 3.5
เราสามารถเรียกสมการนี้ว่า "Multivariate Linear Regression"
ดังนั้น
ก็จะเพิ่มขึ้นตามจำนวนตัวแปรหรือตามจำนวน n ในตารางรูป 3.5
เราสามารถเรียกสมการนี้ว่า "Multivariate Linear Regression"
ดังนั้น

 ใหม่เพื่อเอาไปแทนในสมการ3.2 และ สมการ3.3 จะได้
Repeat Until Convergence {
ใหม่เพื่อเอาไปแทนในสมการ3.2 และ สมการ3.3 จะได้
Repeat Until Convergence {




สรุปจากบทความนี้เราได้ใช้ Gradient Descent algorithm เพื่อนำมาหา Minimize ของ Cost Function ในอัลกอริทึม Linear Regression โดยที่เราสามารถใช้ได้กับข้อมูลที่มีเพียง 1 ตัวแปรหรือ มากกว่า1ตัวแปร